Introduction
I don’t have time to read all of this crap!
Using XML with tSQL
Reading in a list of elements (The Micky Mouse Example)
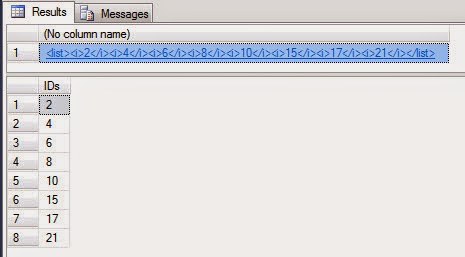
DECLARE @XMLlist XML = '<list><i>2</i><i>4</i><i>6</i><i>8</i><i>10</i><i>15</i><i>17</i><i>21</i></list>'
SELECT @XMLList
SELECT r.c.value('.','int') AS IDs
FROM @XMLList.nodes('/list/i') AS r ( c )
As you can see there is a list of integers being set into an XML parameter. Using the nodes method with it’s XQuery string parameter; the XML is translated into a list of integers by reading each row and the column. Each column’s content is converted to an integer using the value method. This is as basic as it gets, it is useful to play around with, but not useful if you want to pass a multidimensional object (object with multiple properties) aka a matrix. This example is only showing how to convert a list of scalar values – which is definitely not the case most of the time.
Output in SSMS

Passing in an object (More realistic and less “hello worldy”)
As I have pointed out in the previous example, that is just working with scalars. When dealing with objects you are dealing with a matrix or an object with multiple properties. Therefore this example shows you how to read in XML that represents a simple object.
-- Simple object example
DECLARE @xml XML = '<obj><a>John</a><b>Smith</b><c>10</c></obj>'
SELECT @xml
-- Method 1: Full path to each value
SELECT
@xml.value('(/obj/a)[1]','varchar(10)'),
@xml.value('(/obj/b)[1]','varchar(10)'),
@xml.value('(/obj/c)[1]','int')
-- Method 2: Selecting the base node
SELECT
r.c.value('(./a)[1]','varchar(10)'),
r.c.value('(./b)[1]','varchar(10)'),
r.c.value('(./c)[1]','int')
FROM @xml.nodes('/obj') AS r(c)
-- Method 3: Individual hits
SELECT r.c.value('.','varchar(10)') FROM @xml.nodes('/obj/a') AS r(c)
SELECT r.c.value('.','varchar(10)') FROM @xml.nodes('/obj/b') AS r(c)
SELECT r.c.value('.','int') FROM @xml.nodes('/obj/c') AS r(c)
The above is demonstrating three different ways to accomplish the same end result (for the most part). Let’s explore each of these methods (the SSMS output is below this list):
- Full path to each value – Notice there is no FROM clause, this is because the XQuery in the value method is pointing directly to a node using a full path. Notice that there is a “[1]” after value – this isn’t a mistake, it is for selecting the first element found in “node a”.
- Selecting the base node – Notice that there is a FROM clause this time. The reason for this is to declare the path being queried using the nodes method a single time instead of repeatedly declaring it in the value method. This can be more useful for longer paths. The syntax “r(c)” denotes row [r] and column [c] – you can use any letters you want, some people use x and y – I just think r and c makes more sense.
- Individual hits – this is the method being used for the Mickey Mouse example above, notice how inefficient this is with respect to traversing an object – this method requires three queries instead of one and it returns three virtual tables which isn’t terribly useful for querying and I will further show why down below. This is why showing someone how to select a list of integers isn’t an optimal way of explaining to them how to use XML with tSQL.

Writing your XQueries
However before I move on to passing objects from code into stored procedures I am going to give you a query that will help you reduce the amount of time you are spending writing out XQuery strings:
select
TABLE_NAME,
xQueryPath = 'r.c.value(''(./' + column_name + ')[1]'',''' + data_type + '(' + CAST(ISNULL(Character_maximum_length, 0) as varchar(10)) + ')''),'
from YourDatabaseNameHere.information_schema.columns
This query will produced XQueries for each column in all of the tables in your database. The output is just starter code – you still need to manipulate it to make it work properly. This is better than writing it by hand.
The Hard Coding Dilemma and Trade Off at the Cost of Speed
Whenever people would argue with me about hard coding my insert and update queries in code as in-line SQL (assuming the absence of an ORM or Generated Service Layer), everyone always falls back to saying – “hey just use XML”, but I would always throw into their face “Okay, so you want me to hard code XML instead? How is that better?” to which I always just get a broken and distant look. The point is you are going to be hard coding something UNLESS you use XML serialization or some other form of custom serialization – all of which inevitably use reflection.
Reflection will ALWAYS make things slower – however it is far more convenient, almost maintenance free and safer than hard coding XML. This convenience comes at an inconvenience though – the cost of a small performance decrease, but if the point here was to stop the taboo of hard coding SQL in code, then you cannot be a hypocrite and hard code XML instead – that’s just pointless and stupid.
Code for Executing a Non-Query by passing a Target Object as XML
This is code that I wrote for passing a target object as XML to a target stored procedure regardless of what it does. As you have read ad nauseam by this point, the target object is serialized into XML using Magic unless you read the next section to understand how this is done.
//Using blocks required
using System.IO;
using System.Xml;
using System.Xml.Serialization;
protected int ExecuteNonQuery<T>(T anyObject, string storedProcedureName)
{
SQLText = ConstructXmlArguments(anyObject, storedProcedureName);
//This method is not provided to you in this example - use a basic Execute Non Query method here
return ExecuteNonQuery();
}
protected int ExecuteInsert<T>(T anyObject, string storedProcedureName)
{
SQLText = ConstructXmlArguments(anyObject, storedProcedureName);
//This method is not provided to you in this example - use a basic Execute Insert or Execute Scalar method here
return ExecuteScalar().ConvertToInt32();
}
//This method is fully functional on its own and does not need to be modified
public static string SerializeToXmlString<T>(T anyObject)
{
string strXML = string.Empty;
XmlSerializer ser = new XmlSerializer(typeof(T));
//Setting the namespace to nothing on purpose
XmlSerializerNamespaces ns = new XmlSerializerNamespaces();
ns.Add(string.Empty, string.Empty);
//Setting the rest of the xml writer settings to remove inconvenient parts for tSQL
XmlWriterSettings settings = new XmlWriterSettings();
settings.Indent = false;
settings.NewLineHandling = NewLineHandling.None;
settings.OmitXmlDeclaration = true;
//Write everything into memory
using (MemoryStream ms = new MemoryStream())
{
//Write the XML to memory
using (XmlWriter xmlWriter = XmlWriter.Create(ms, settings))
{
ser.Serialize(xmlWriter, anyObject, ns);
}
//Rewind
ms.Position = 0;
//Read the stream into a string
using (StreamReader sr = new StreamReader(ms))
{
strXML = sr.ReadToEnd();
}
}
return strXML;
}
Please note that this is the partial implementation and that this code was taken from a DAL that I wrote. You need to retrofit it to work with your DAL that you intend on using it with, the above code is for basic idea and reference only.
SerializeToXmlString Method
- The default XML Namespace – it is blank on purpose
- Removed indents
- Removed new lines
- Removed the XML Document tag
- As usual though, if you try to serialize an object that is not serializable, you will end up having a run time error. This is not out of the norm.
- If someone removes or renames a class property, they have to be conscious enough to know that they must now go alter the accompanying Stored Procedures. This is a definite con when relying on a Serializer. Had the XML been hard coded, this would not matter at all. If the XML is hard coded then:
- In the case of removing a property – you would not be able to compile the code unless you modified that XML as well – in which case you know you need to update the Stored Procedure(s)
- In the case of renaming a property – you could rename the property and forget to update the XML without worrying about causing any run time errors. I am not saying this is proper, I am just saying it wouldn’t cause a problem.
This is what the default output would be for a “Bob” object if you did not configure the serialization manually. None of this is okay for usage because the xml document tag shows up, the namspaces (xmlns:{xxx}) are listed and there are indentations (tab characters) and new lines (carriage return and line feed characters).
<?xml version="1.0" encoding="utf-16"?>
<Bob xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Name>Bob the 5th</Name>
<MaryInstance>
<IsMary>true</IsMary>
</MaryInstance>
<MaryInstance2>
<IsMary>false</IsMary>
</MaryInstance2>
<Age>62</Age>
</Bob>
The main difference to note here is how this example adheres to every bullet point in the list above. The XML is all on one line and it is very simplistic.
<Bob><Name>Bob the 5th</Name><MaryInstance><IsMary>true</IsMary></MaryInstance><MaryInstance2><IsMary>false</IsMary></MaryInstance2><Age>62</Age></Bob>
Consuming the XML
The Bob class (Bob.cs if you will)
This is a very flat class purely for demonstration purposes. An instance of this class is serialized into XML.
public class Bob
{
public string Name { get; set; }
public string Occupation { get; set; }
public int Age { get; set; }
public string Mood { get; set; }
public DateTime CreatedOn { get; set; }
}
Bob Object Serialized
I am showing the Bob object formatted here for readability, no one wants to read this crap on a straight line – just keep in mind, during run time this will be on a straight line for all of the reason listed above. Note the format of the CreatedOn node value. This is passed to the stored procedure.
<Bob> <Name>Bob the 5th</Name> <Occupation>Fast Food Engineer</Occupation> <Age>40</Age> <Sex>None Yet</Sex> <Mood>Resentful of others</Mood> <CreatedOn>2014-11-18T22:30:42.4817743-04:00</CreatedOn> </Bob>
Bob Insert Stored Procedure
As you can see in the the tSQL below, the Bob object is being inserted directly into the Bob table, there are no other intermediary transfer parameters. This would be different with an Update Statement I would imagine. Note how the CreatedOn node is being handled.
CREATE PROCEDURE [dbo].[Bob_NewBob]
@parameters XML
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO [dbo].[Bob]
([name]
,[occupation]
,[age]
,[sex]
,[mood]
,[createdOn])
SELECT
r.c.value('(./Name)[1]','varchar(100)'),
r.c.value('(./Occupation)[1]','varchar(100)'),
r.c.value('(./Age)[1]','int'),
r.c.value('(./Sex)[1]','varchar(20)'),
r.c.value('(./Mood)[1]','varchar(255)'),
CAST(r.c.value('(./CreatedOn)[1]','varchar(35)') as datetime2)
FROM @parameters.nodes('/Bob') AS r(c)
END
XML to tSQL Gotchas!
There are two very important things to note when working with XML and tSQL (that I have found to be very obscure so far):
- Casing matters! When you are writing your XQueries – the node names are case sensitive. Therefore if your class Properties are beginning with an upper case letter, then your node names are going to use an upper case letter etc… Therefore if you run into a weird parsing error where a column cannot be found, it is because of the casing more than likely.
- There is no simple way to cast an XML serialized DateTime node value into a datetime2 sql parameter – you must do as I have shown above which is a double cast basically. First convert to a varchar(35), then cast that string to a datetime2. I have looked into changing how the XML serializes and formats the DateTime objects, but it is far more trouble than it is worth – this is a much easier approach.
Conclusion
Yeah… so “Just use XML” huh? So simple… I appreciate the journey that I went through learning about all of the trouble of just using XML, but it does feel like a bit much just to avoid using in-line SQL. The good news is once you are finished writing the code, it isn’t a big deal anymore, but this took a few hours for me to understand (hence the article as documentation). I cannot say this was simple. Lastly there is definitely the trade off of using an XML Serializer.
I honestly don’t think in-line SQL is too bad and I think it get’s a bad wrap because people just don’t implement it properly. It just depends on it’s usage scenario. For example I think SELECT statements should always be stored procedures regardless of their simplicity, but if this is a SELECT statement that is being constructed on the fly using Dynamic SQL in a stored procedure – I would rather do that in code depending on the complexity because it is much easier to work with in code, than it is to do in a stored procedure – not to mention using business logic in stored procedures is a worse taboo than in-line SQL is. The reason for this is simple, now you have to maintain logic in two places instead of one – this is NEVER okay and leads to bad programming practices and spaghetti code.
Dynamic SQL in Stored Procedures is abused horribly by a lot of developers. I have seen some very bad practices in Stored Procedures which mostly involve a lot of copying and pasting of queries with minor differences in the where clause or joining on the dogs table if the cat bit is set to zero or null. My point is Dynamic SQL in Stored Procedures is more of a determent than a help if you have the wrong people working with it. Anytime someone introduces duplication, they are writing bad code aka Spaghetti code. If you are having a very hard time representing something in SQL you should probably consider NOT writing it in SQL and just do it in code instead… you know where the business logic lives.
People like to argue that you should use parameterized queries in code instead of in-line SQL and I strongly disagree. The only attractiveness that parameterized queries have is protection against SQL Injection – other than that – the amount of overhead of writing the code for this is ridiculous and I would rather not. This is not me being lazy, this is me saying I would rather just use a stored procedure if I am going to go through the trouble of writing one in code, which is basically what parameterized queries are. Other than protection against SQL Injection, the only usefulness I have found in parameterized queries is the insert and update operations for blobs (byte arrays). That’s it. Frankly that is all I will use it for – other than that it is inflexible and overkill to use.
If your code is not written in a way where you are not protecting yourself from SQL Injection attacks – then you deserve to be hacked and lose your data. Stop being lazy and do it right.