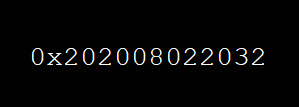
A practice I have engaged in for a long time now is adding error codes to any custom or handled exceptions that are thrown on purpose in an
application. The purpose of these error codes is to act as an anchor in the code. The error code is unique, human readable, will not change and is text searchable in both code and in logs. Therefore, even though the error code isn’t pretty, it is useful for debugging purposes, but it is meaningless to the users if they do see it. The way I decided to use error codes keeps the actual content anonymous to the outside, but it means something to us. It is just an identifier and it is very easy to produce.
Why should I use this methodology?
It takes the guess work out of making a unique identifier and it is more legible than a GUID. It is guaranteed to be a unique identifier because the likelihood of two developers creating brand new custom exception code at the same time is very slim. The worst that can happen is that two developers are coding an exception and happen to use the same code, this is easily fixed and nothing to cry over.
When producing an exception message, you no longer have to worry about dynamic strings making it difficult to locate your exception in logs or
locating them in code. The whole point of this error code is to append it to the end of your message. As long as the error code is present in the
message, your message can change as often as you need it to and you will always be able to find your errors in the log and in your code. These identifiers also show the age of certain areas of code. Since it is just a timestamp you can know when something was established.
What prompted you to come up with this methodology?
Dynamic messages
Anonymous or dynamic exception messages are bad!
Code like the following is almost untraceable in some aspects. Because so many parts of the string are dynamic, trying to group together these exceptions is really difficult since the strings are inconsistent. You also don’t want to have to do multiple wildcard searches on a text field of your log table, this is really slow.
public void Example()
{
//Critical code here, the validation failed
//Imagine these parameters are actually filled out with something useful
int intInvoiceId;
decimal decAmount;
string strUserName;
if(!condition)
{
throw new Exception($"Invoice [{intInvoiceId}] for amount {decAmount} could not be processed. Initiated by {strUserName}.");
}
}Therefore, my methodology ignores everything to the left of the string, you can put whatever crazy stuff you want in there, so long as you have an identifier appended to the end of the string so you know what to look for.
The following is the exact same code just with the error code appended to the exception. Adding a constant string makes it easier to find when searching through logs.
public void Example()
{
//Critical code here, the validation failed
//Imagine these parameters are actually filled out with something useful
int intInvoiceId;
decimal decAmount;
string strUserName;
if(!condition)
{
throw new Exception($"Invoice [{intInvoiceId}] for amount {decAmount} could not be processed. Initiated by {strUserName}. 0x202008021949");
}
}Simplifying your search
What this boils down to is tractability and simplifying your search. Searching for a dynamic string is an annoying task when you don’t know what parts of the string are dynamic. Therefore, when values are constantly changing it’s basically impossible to quantify how often an error shows up until you know what the exact template is. This is why I strongly suggest having a unique identifier in the dynamic error message to find it. Think of this as an anchor in the message.
Anchor
I have come across some rather annoying exception generating code that is very unhelpful when you are trying to find out where the exception originates. I am talking about something like this:
public void Example()
{
var svc = new SomeServiceClass();
var strError = svc.DoThing();
if(strError != "")
{
throw new Exception(strError);
}
}This code is less than ideal, there are a lot of problems with it starting with how a string is being used to determine if a method succeeded or didn’t – regardless I have seen terrible code like this whether it was from an old COM object or from a novice developer. The point here is to focus on how that “throw new Exception” line can throw anything. Therefore, trying to figure out where this is originating is rather difficult sometimes because you cannot always be guaranteed to get a stack trace back.
public void Example()
{
var svc = new SomeServiceClass();
var strError = svc.DoThing();
if(strError != "")
{
throw new Exception(strError + ":: 0x202008022005");
}
}Now if you have a static string as part of the returned error message you can always find where this problem is occurring. Hopefully after finding something this horrible you have the wisdom to fix it.
Dynamic strings
-- This will find all occurrences of an exception (or piece of information) regardless of the error message
SELECT * FROM dbo.Log WHERE Message LIKE '%0x202008022008%'This is an example of how simple it is to find the occurrences of an exception or general message in your log.
How to create an error code
These error codes are not complex or cryptic. It was meant to be simple so that developers don’t have to coordinate with one another on which error codes they are using. You should only produce and use an error code when throwing an exception. It can be used for logging information, but I don’t believe in logging information in an exception log.
Chances are no one is going to be looking for information entries in an error log except for the one person who thought it was useful for that one feature they were implementing a year ago. Therefore, it is better if you do not use it for any other reason but for exceptions. Keep your logs clean, less noise, mean less rows and makes it easier to deal with over all.
Guidelines
- An error code consists of just two or three parts.
- It will always be composed of two parts at the minimum
- The third part is entirely optional
- Do not use dynamic strings to produce error codes as this defeats the purpose entirely
- The purpose of an error code is to be used as an anchor in the code
- Only use today’s time stamp, never use a time stamp from the past
- If you need to generate multiple error codes in the moment, just increment the minute
- The likelihood that someone else is doing this at the same time is essentially nil, so this is safe to do
Schema
| Prefix | Date & Time | Optional Constant String | Combined | |
|---|---|---|---|---|
| Structure | 0x | yyyyMMddHHmm | A | 0xyyyyMMddHHmmA |
| Example | 0x | 202008022018 | A | 0x202008022018 |
Why is there a prefix of zero and lowercase x?
If you have ever seen a hexadecimal memory address, the prefix denotes hexadecimal, but really, I chose it just because it is reminiscent of that idea. To me it just denotes “This is an address”, plain and simple. An example of the hexadecimal equivalent of 1024 is 0x400.
Why would I need the optional constant string?
You can suffix the error code with a constant string if you are trying to denote a sub location. I don’t recommend going overboard with this, keep it short. The benefit to doing this is that when you are querying for your errors in a log you can see how many errors of that error code occurred, but if you want to know only about one sub location then you can include the suffix in your search.
Think of it as a type of grouping. However, I only recommend doing this when you have multiple exceptions being thrown if certain conditions are being met such as when performing validation. You can eyeball where in the process something failed.
Examples
The example scenario here is that all of these errors are part of the same area of code such as a method. The base error code is “0x202008022023”. Imagine this code sends email.
| Error code | Suffix | Meaning |
|---|---|---|
| 0x202008022023A | A | “To” email address not provided |
| 0x202008022023B | B | Malformed “TO” email address |
| 0x202008022023C | C | Etcetera |
Error code dictionary
Eventually you will rack up enough error codes that it probably merits having a dictionary so you can look up the reason behind the error. I strongly suggest documenting your error codes. You have the added benefit of just doing a global search, such as “Ctrl + Shift + F” in Visual Studio, that will take you right to that place in the code so you can conduct investigations.